The collective exhaustion inside enterprise data departments is palpable. For the past few years, the corporate world has been locked in an intense love affair with the chat box. Leaders promised that giving every employee a generative AI “Copilot” would democratize analytics, eliminate backlogs, and instantly transform raw data lakes into clean operational insights.
Instead, organizations ended up with prompt fatigue.
Data analysts and business executives did not log into work to become full-time prompt engineers. They do not want to spend twenty minutes tailoring a paragraph of hyper-specific text just to extract a standard regional sales chart or a inventory variance report. The reactive, chat-driven model of first-generation AI assistants has hit a structural ceiling. It relies entirely on human initiative, human data literacy, and the flawed assumption that users know exactly what to ask.
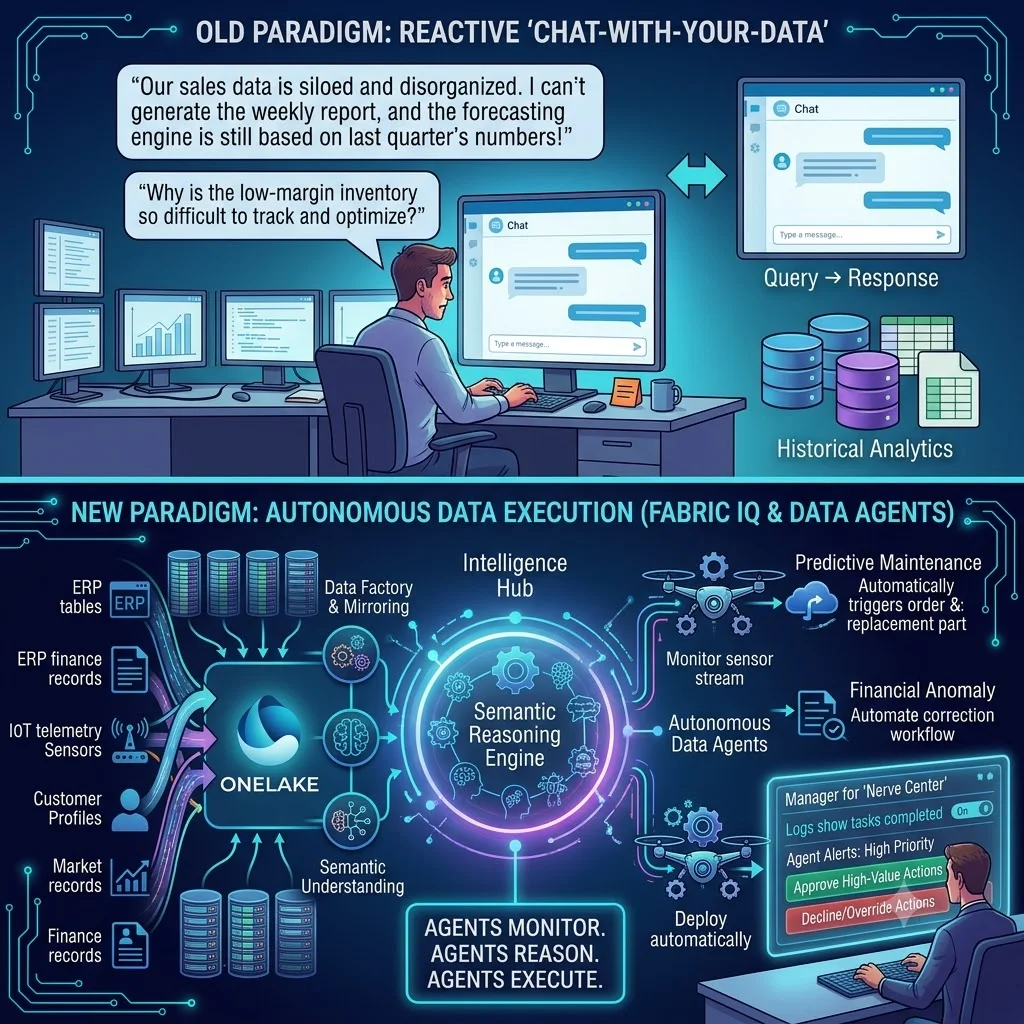
We are entering the next phase of enterprise intelligence: the transition from passive assistance to autonomous execution. The era of typing queries into a text box is giving way to background intelligence networks driven by architectures like Microsoft Fabric IQ and autonomous Data Agents. This shift marks a fundamental relocation of AI from a conversational sidekick to an active, always-on team member that monitors data streams, models decisions, and executes operations without waiting for a command.
-
The Limits of First-Generation GenAI Copilots
To understand why enterprise architecture is shifting, we have to look closely at the architectural and operational friction points of early AI copilots. First-generation systems operate primarily as stateless translation layers. They take a user’s natural language prompt, convert it into SQL, DAX, or Python, execute that code against a database, and return a text summary or a chart.
While this looks impressive in a controlled demo, it introduces three significant points of friction in an enterprise environment:
The Data Literacy Tax
A copilot is only as effective as the person asking the question. If a business manager does not understand the structural difference between “gross booked revenue” and “recognized net revenue,” their prompt will yield flawed metrics. Copilots do not fundamentally correct a lack of data literacy; they simply accelerate the production of poorly contextualized answers. When users don’t know what anomalies to look for, a traditional copilot sits completely idle.
Context Window Degradation and Semantic Drift
Standard Large Language Models (LLMs) operate within strict context limitations. When a user conducts an extended analytical session, conversational history grows. Over time, the model suffers from semantic drift—forgetting initial constraints, mixing up dimensional filters, or hallucinating connections between completely unrelated tables. This makes deep, multi-step data exploration highly unreliable in standard chat interfaces.
Siloed Data Access and Latency
Most first-generation copilots are bolted onto isolated applications. CRM copilots only see pipeline data; ERP copilots only see inventory data. To answer a complex cross-functional question like “How are regional shipping delays impacting customer churn risk in our high-margin segments?”, a user must manually prompt multiple tools, export disparate CSV files, and stitch the narrative together themselves. This workflow fails to deliver on the true promise of unified data intelligence.
-
Enter Fabric IQ and Unified Data Intelligence
Overcoming these limitations requires a complete structural overhaul of how data is stored, indexed, and made available to artificial intelligence. This is the exact design challenge that Microsoft Fabric addresses, specifically through its central intelligence layer: Fabric IQ.
Rather than trying to pass massive chunks of raw data back and forth across different cloud boundaries to an isolated LLM, Microsoft Fabric consolidates enterprise data into a single, unified, logical data lake known as OneLake. Within this architecture, data is stored in an open, standardized format (Delta Parquet) using V-Order serialization for lightning-fast analytics performance.
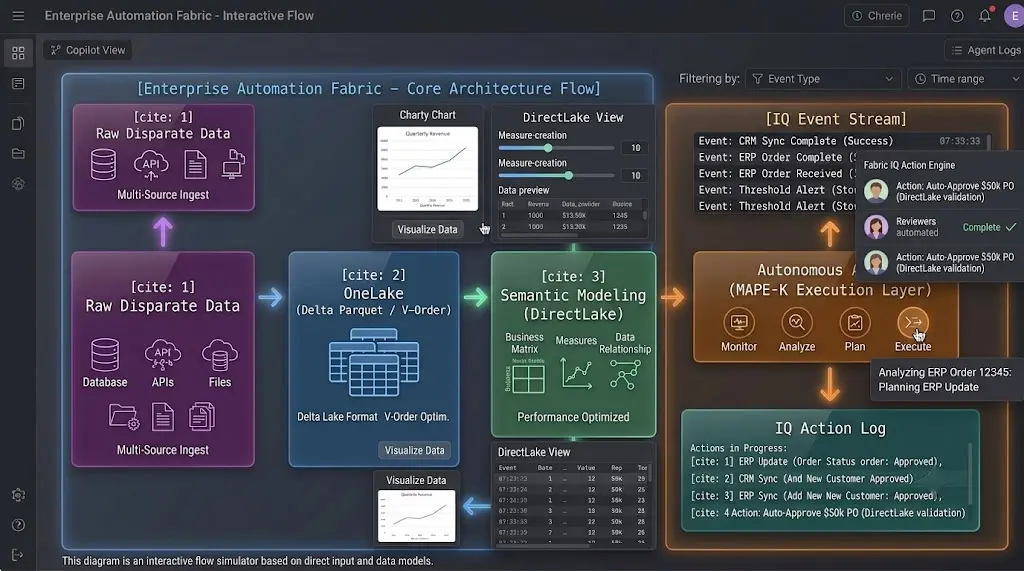
Fabric IQ functions as the native organizational brain built directly into this data foundation. Because it sits inside OneLake, it does not need to move data to reason over it. It bypasses traditional, high-latency Extract, Transform, Load (ETL) pipelines entirely. Fabric IQ reads metadata, monitors access logs, and interprets semantic definitions continuously.
When data models are structured correctly, Fabric IQ understands the precise relationships between complex tables natively. It knows that a Customer_ID in the billing engine correlates exactly with a Client_Ref in the logistics ledger, even if no explicit foreign key relationship is defined in a relational database.
However, achieving this level of autonomous clarity requires an immaculate underlying data strategy. Fabric IQ cannot interpret chaos. Organizations cannot simply point an autonomous intelligence layer at an unorganized data swamp and expect flawless execution. This reality has fundamentally changed the role of data consulting partners. Modern enterprises routinely partner with a specialized Power bi consulting company to build out robust, enterprise-grade semantic layers, optimize DirectLake connection models, and craft standard DAX measures. This foundational engineering guarantees that when Fabric IQ scans the organizational data landscape, it reads a single, highly accurate source of truth rather than contradictory data silos.
| Layer Component | Primary Technical Function | Impact on Enterprise AI |
| OneLake Storage | Multi-cloud data virtualization using Delta Parquet open standards. | Eliminates data duplication and reduces data movement latency to zero. |
| DirectLake Engine | Loads Parquet files directly from OneLake storage into memory without import or DirectQuery overhead. | Allows AI models to query petabyte-scale data models in milliseconds. |
| Fabric IQ Semantic Parser | Continuously reads semantic models, schemas, and operational metadata. | Prevents model hallucinations by enforcing unified business logic and terminology. |
| Managed Security Guardrails | Direct row-level (RLS) and object-level security (OLS) inheritance. | Ensures the AI never exposes restricted financial or HR data to unauthorized users. |
-
From Chatbots to Data Agents: The Architecture of Execution
If Fabric IQ represents the central nervous system of modern data architecture, Data Agents represent the hands and feet.
The core distinction between a copilot and a data agent comes down to autonomy, state preservation, and execution pathways. A copilot requires an explicit input event to trigger a single output event.

An autonomous Data Agent is designed with a persistent objective rather than a temporary query window. For instance, an agent might be given the permanent objective: “Maintain localized inventory levels across all distribution centers to prevent stockouts while minimizing holding costs.”
To fulfill this objective, the agent does not sit around waiting for a supply chain manager to type a message. It runs continuously in the background, executing a structured loop:
- Perception: The agent monitors real-time streaming data within Fabric, tracking purchase orders, historical telemetry, fleet updates, and incoming sales velocities.
- Reasoning: It leverages Fabric IQ to run predictive modeling over these streams, identifying that a pending shipping delay in a specific shipping lane will cause an inventory deficit for a high-priority product line within 48 hours.
- Action: Instead of merely presenting a notification that reads “You have a problem,” the agent initiates an automated mitigation workflow.
To bridge the gap between analytical insights and system-wide transactional operations, data engineers deploy targeted execution frameworks. Organizations lean heavily on a certified Power automate consultant to construct secure, reliable background workflows, API hooks, and cloud flow triggers. These flows allow the Data Agent to interact directly with external legacy systems that automatically drafting a purchase order, routing it through an approval chain, or adjusting safety stock thresholds in a core ERP system without demanding manual data entry from a human analyst.
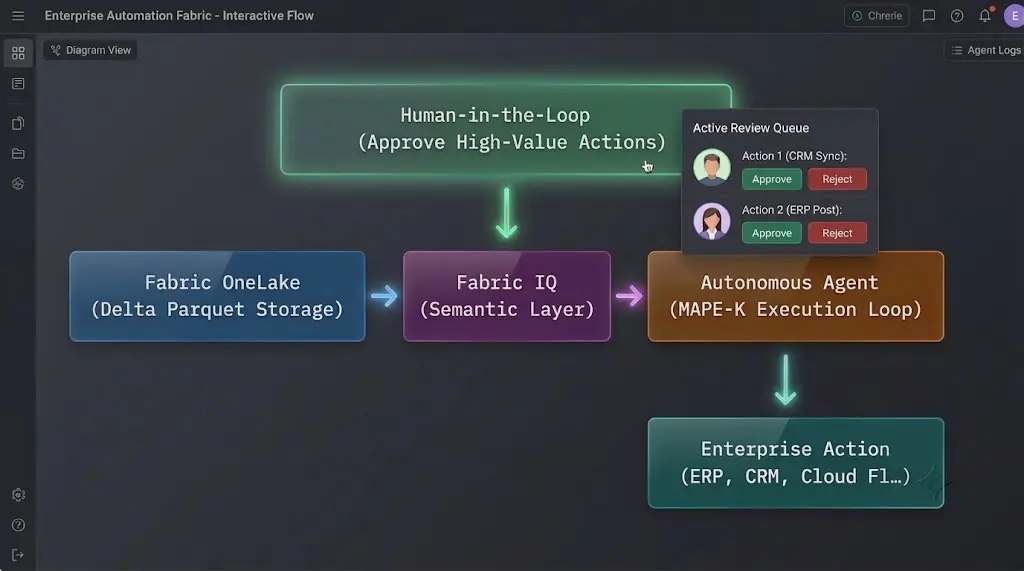
Furthermore, deploying these autonomous frameworks across varied geographical regions requires tailored interface construction and ironclad operational governance. Large enterprises frequently engage with localized development specialists, utilizing resources like Power apps consulting services Texas to build custom, low-code operational nerve centers.
These tailored applications serve as a critical control layer. They provide on-the-ground operational teams with clean dashboards to monitor autonomous agent behavior, review automated decision logs, and manage “human-in-the-loop” approval parameters for high-value transactions. This balance ensures that while the agent runs autonomously at scale, local business operations maintain total transparency and strategic veto power over automated actions.
⚠️ Critical Industry Warning: The Governance Imperative
Granting autonomous Data Agents the authority to modify workflows, trigger cloud flows, and interact directly with production systems introduces substantial operational risk. If an agent misinterprets a data anomaly, it could easily trigger chain-reaction system errors across your supply chain or ERP.
Organizations must implement a zero-trust data governance policy:
- Never grant data agents direct write access to transaction ledgers without human-in-the-loop validation rules for values above a strict financial threshold.
- Ensure all agent actions, underlying reasoning tokens, and API payloads are written to an immutable ledger for continuous security auditing.
- Bind agent execution logic tightly to the data access permissions of the specific user or service principal invoking them.
-
Real-World Use Cases: What Autonomous Data Execution Looks Like
To move past theoretical architecture, let us analyze how the combination of Fabric IQ and autonomous data agents transforms day-to-day operations across major enterprise sectors.
Financial Anomaly Detection and Automated Ledger Correction
In traditional corporate finance, identifying transactional discrepancies is a grueling, retrospective process. Teams perform reconciliations weeks after a billing cycle closes.
In an agentic data ecosystem, a Financial Data Agent runs continuously against incoming transactional data streams in OneLake. If an invoice line item deviates from a validated master service agreement (MSA) framework, the agent flags the variance instantly. It cross-references historical contract data via Fabric IQ, identifies the precise root cause of the billing mismatch, drafts an electronic credit memo, and queues it up within the company’s accounting software for immediate review by a controller.
Predictive Maintenance and Automated Supply Chain Ordering
In modern heavy manufacturing facilities, unexpected machine downtime can cost millions of dollars per hour.
Instead of an engineer having to periodically run queries on equipment health, a Predictive Maintenance Agent tracks real-time vibration, temperature, and performance telemetry directly inside Fabric’s Real-Time Intelligence engine. When a component displays micro-patterns indicating imminent failure, the agent calculates the remaining useful life of the part. It automatically searches the current maintenance schedule, checks OneLake inventory counts for replacement parts, and routes a digital work order directly to an available technician’s device, completely automating the preventive response loop.
-
Conclusion: Preparing for the Agentic Shift
The competitive advantage in modern enterprise technology is shifting rapidly. The value is no longer in knowing how to phrase a clever question to a chat window; it lies in knowing how to build, deploy, and orchestrate autonomous systems that eliminate the need for manual questioning entirely.
Organizations that continue to treat generative AI as merely an alternative interface for standard search queries will inevitably fall behind. By consolidating data infrastructure on unified foundations like Microsoft Fabric, establishing precise semantic models, and deploying targeted Data Agents, forward-looking enterprises can transition from a reactive posture to a proactive state of continuous operational optimization. The message is clear: stop prompting your data, and build the autonomous systems that allow it to execute for you.